Why Every Tool in the Modern Data Stack Needs Git
Leverage the power of software development and DevOps and implement the same best practices you use in your production code in the context of data integration with Git.

Pedram Navid

Ernest Cheng

Luke Kline
November 9, 2021
4 minutes
How Does This Work Behind the Scenes?
When we built this integration, we had a few design choices that we believed were critical to its success. We wanted to create a native integration with Git that felt painless while avoiding some of the headaches that often come with other infrastructure-as-code projects.
State changes can be really hard to deal with and we didn’t want to force users to pick between making changes in the UI or via Git and the command line. Anyone who’s had a sleepless night trying to reconcile Terraform state changes before making a small change knows this pain all too well.
We also believed that observability and auditing should be first-class concepts. It wasn’t enough to simply sync changes between Git and Hightouch. We wanted to capture changes to all resources and commit those individually, to make roll-backs and cherry-picking easy. To that end, we came up with the following underlying architecture:
First, Hightouch implements syncing in two directions:
- Hightouch to Git (outbound)
- Git to Hightouch (inbound)
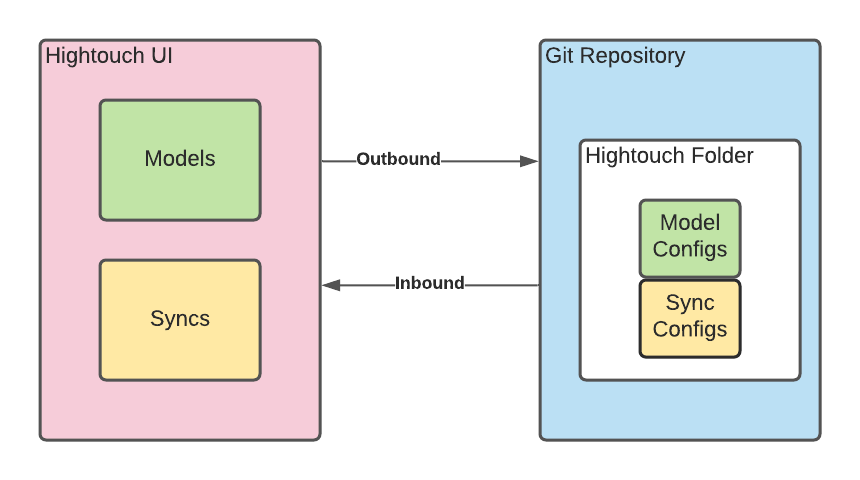
For the outbound direction, Hightouch keeps an audit log of changes made to all resources, e.g. configuration changes, schedule changes, and so on. On a fixed interval, we check the audit log to see which resources have changed and sync the new versions out to the Git repository.
We make an individual commit per resource, enabling users to roll back any unintended changes made in the Hightouch UI.
For the inbound direction, Hightouch looks into the Git repository and checks the state of every resource with the state in Hightouch. For each of those changes, we sync the new version into Hightouch, whether it’s a small change or a completely new resource.
There are some particular nuances that help us reduce the possibility of edge cases:
- We run the inbound sync, if and only if, the outbound sync was successful.
- We have added a required slug on every resource to help users identify resources. without the need for an uninformative ID. This is also useful if we’re creating resources directly inside Git.
How Do You Get Started?
Read our docs here to get started with Git Sync.





